2012
di Federico Pinca, Aethia Srl
A & C - ANALISI E CALCOLO | MARZO 2012
BLCR (Berkley Lab Checkpoint/Restart) è un modulo del kernel che permette a programmi in esecuzione su sistemi Gnu/Linux di salvare il proprio stato interamente in un file e successivamente essere riavviati tramite le informazioni scritte nel momento del “checkpoint". E' un progetto sviluppato dalla FTG (Future Technologies Group) con lo scopo di creare una soluzione senza modificare codice delle applicazioni supportate, con attenzione particolare al message-passing system MPI.
In questo articolo, un breve sunto delle pubblicazioni degli sviluppatori, raccolta di materiale, e una breve analisi di uno scenario. Si illustra in breve il progetto, magari per suscitare curiosità nel lettore.
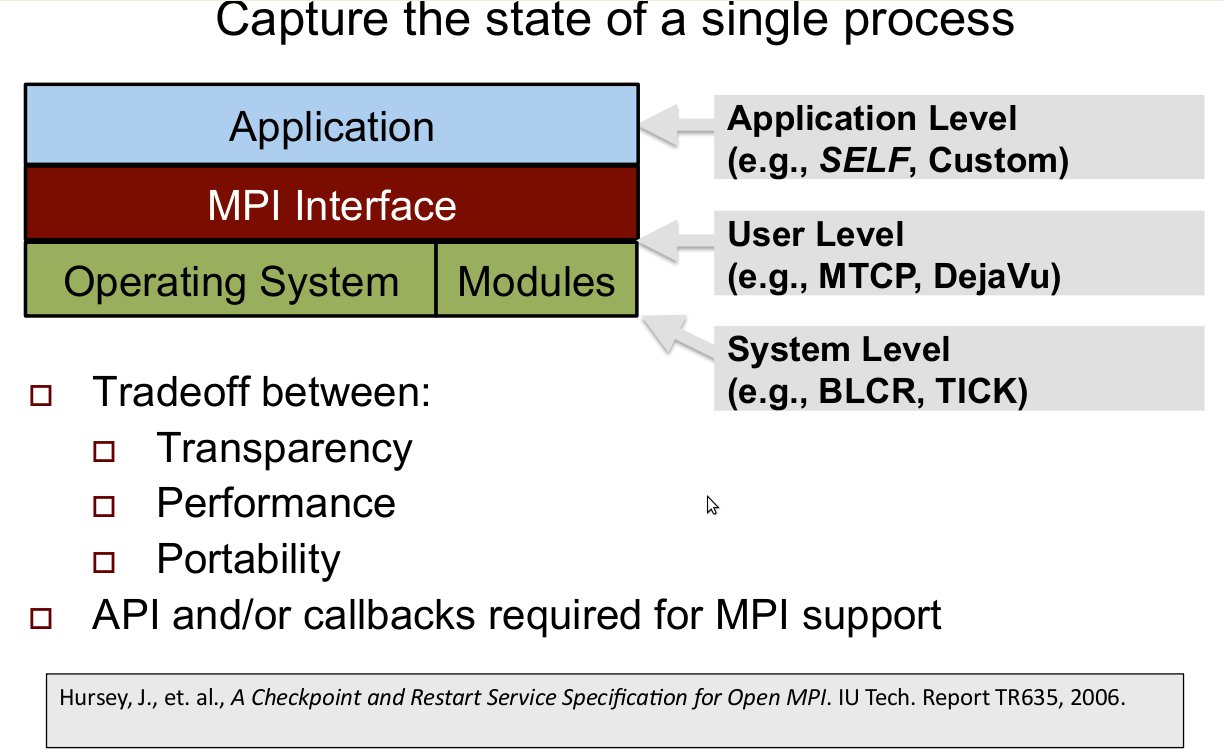
Cos'è BLCR?
BLCR è sostanzialmente un modulo per il kernel Gnu/Linux, quindi meno portatile di altre soluzioni a livello utente, ma per la sua natura ha accesso a tutte le risorse a cui ha accesso il kernel: per esempio può congelare gli script di shell ed i suoi sotto-processi insieme con le pipe che li collegano, ed anche programmi multithread.
Non supporta però il ripristino dei socket (TCP/IP, Unix) aperti, fondamentali nelle applicazioni che comunicano tramite MPI, ma per questo c'è soluzione.
BLCR permette, anche in maniera semplice, di implementare funzioni di callback a livello utente facili da integrare nelle librerie/applicazioni su cui si vuole usare il checkpointing, che vengono eseguite quando appunto si vuole fare il backup dell'esecuzione in corso, e che continuano al ripristino; tramite questi callback si consente all'applicazione di chiudere i propri socket o altri processi non congelabili senza perdita di dati o non “restartabili" prima che una azione di checkpoint sia eseguita.
Un possibile scenario, Maui's Preemptee e Preemptor classes, con Torque.
Maui è un job scheduler open source per supercomputer, con ampie capacità di configurazione che spaziano dal fairshare alle policy di allocazione dei nodi, ed alla priorità dei job: è tutto poi nelle mani degli amministratori/utenti scegliere i parametri e le molteplici possibilità che soddisfino le proprie richieste.
Le due classi sopra citate sono degli attributi di priorità assegnabili alle code (QOS), un job lanciato nella coda marcata come Preemptor avrà la possibilità (anche qui Maui offre varie soluzioni) di modificare lo stato di un preemptee job di minore priorità, per accedere alle risorse necessarie alla propria esecuzione; questo meccanismo migliora le percentuali di utilizzo delle macchine e fornisce un eccellente turnaround per i lavori considerati importanti.
Le possibili regole di preemption sono tre: REQUEUE, SUSPEND e CHECKPOINT. Perché sospendere un job che magari è in esecuzione da giorni (anche se considerato a priorità minore) quando possiamo salvarne e conservarne lo stato per permettere poi a Maui di riavviarlo quando vengono liberate nuovamente delle risorse?
Nel nostro scenario, Maui chiede a Torque di compiere una delle 3 possibili azioni sul job, in questo caso il CHECKPOINT, e qui entra in gioco BLCR: fino a qualche tempo fa il checkpointing era limitato alle capacità della macchina o ad alcuni particolari applicativi, ma dalla versione 2.4 di Torque vi è il pieno supporto al modulo in questione.
Il tutto si raggiunge con alcuni parametri da presentare a Torque-Mom:
- $checkpoint_interval – Ogni quanto tempo viene eseguito un checkpoint di un job (minuti).
- $checkpoint_script – Lo script da eseguire per ottenere un job checkpoint.
- $restart_script – Lo script da eseguire per ottenere la ripartenza del job.
- $checkpoint_run_exe – Il nome dell'eseguibile da caricare quando viene lanciato un job che supporta il checkpoint (per BLCR, cr_run).
Ci terrei a sottolineare la prima opzione elencata, utile per possibili backup a stati per job “importanti". Questo ovviamente ha un costo in termini di risorse utilizzate, questi alcuni test con MVAPICH.
BLCR altri scenari, “fault tolerance"
Come già si evince dall'esempio precedente, meccanismi di checkpointing dei job sono solo una delle possibilità di riflessione e sviluppo di “fault tolerance" nei sistemi HPC, cioè l'abilità di recupero da guasti di componenti, sia con meccanismi trasparenti o orientati alle applicazioni.
Un'applicazione HPC deve essere elastica per sostenersi in caso di perdita di processi a causa della elevata probabilità di guasto hardware dei moderni sistemi.