2011
di Gianpaolo Perego, Aethia Srl
A & C - ANALISI E CALCOLO | SETTEMBRE 2011
All'incirca ogni 10 anni il mondo del supercalcolo vive un cambiamento fondamentale a livello architetturale. Circa 10 anni fa il calcolo basato su cluster ha soppiantato quello basato su supercomputer vettoriali, diventando lo standard di fatto per tutti i tipi di installazioni e portando l'industria del supercomputing oltre la barriera del petaFLOP. Con l'exascale-computing come prossimo obiettivo è tempo oggi per una nuova rivoluzione, quella del calcolo massivamente parallelo, di cui il GPU computing, o GPGPU, è una delle espressioni principali.
GPGPU sta per General-Purpose computation on Graphics Processing Units. Le GPU (Graphics Processing Units) sono oggi processori multicore dalle alte prestazioni, capaci di elevati livelli di potenza di elaborazione e throughput. Inizialmente progettate per la computer grafica e abbastanza difficili da programmare, le GPU di oggi sono processori paralleli adatti a tutti i compiti, con supporto per interfacce di programmazione accessibili e rispetto dei principali standard industriali (es. linguaggio C). Gli sviluppatori che portano le loro applicazioni su GPU spesso ottengono speedup di diversi ordini di grandezza rispetto alle analoghe implementazioni su CPU.
_2017-11-09-16-11-14.png)
Le GPU possono processare solo elementi indipendenti, ma possono farlo su un gran numero di elementi in parallelo. In questo senso le GPU possono essere considerare stream processors ossia processori in grado di operare in parallelo applicando uno stesso kernel su un gran numero di set di dati all'interno di una sequenza. Uno stream è semplicemente un insieme di record sui quali devono essere compiute operazioni simili. Un kernel è una funzione che viene applicata ad ogni elemento dello stream.
Il fatto che le GPU diano i risultati migliori quando è possibile suddividere un problema di calcolo in un gran numero di task elementari indipendenti fra loro, fa sì che non tutti i problemi possono avvantaggiarsi significativamente dalla potenza di calcolo delle moderne GPU. Alcuni ambiti in cui si ottengono vantaggi tipicamente elevati sono l'elaborazione di immagini in genere (es. immagini mediche, rendering), la ricerca geologica (es. ricerca di giacimenti petroliferi e di fonti naturali), oltre che l'analisi di modelli di rischio finanziari. Altre categorie di applicazioni meno adatte al GPU computing per la natura stessa degli algoritmi coinvolti sono i database, la compressione di dati e gli algoritmi ricorsivi in genere.
Uno dei player principali del panorama GPGPU è NVIDIA, che per prima ha investito su questo fronte e propone oggi prodotti specifici per il calcolo sia a livello hardware (schede Tesla/Fermi) che software (CUDA). In particolare CUDA (acronimo di Compute Unified Device Architecture) è un'architettura di elaborazione in parallelo che permette ai programmatori di scrivere applicazioni capaci di eseguire calcoli in parallelo sulle GPU NVIDIA utilizzando i linguaggi di programmazione più diffusi in ambito scientifico (C, Fortran, Python, Java).
Da alcuni anni è stato introdotto sul mercato anche lo standard OpenCL (Open Computing Language),oggi promosso dal consorzio no-profit Khronos Group, OpenCL è una libreria basata sul linguaggio di programmazione C99, che può esser eseguito su una molteplicità di piattaforme CPU, GPU e altri tipi di processori.
I benefici dell'utilizzo di una GPU per svolgere elaborazioni di tipo diverso dall'ambito grafico, sono molteplici e tra questi si possono ricordare i seguenti:
- Vantaggi prestazionali: dal punto di vista puramente prestazionale si possono ottenere incrementi anche di 100 volte rispetto a quanto offerto dalle tradizionali CPU; va detto comunque che il passaggio dell'elaborazione del codice verso la GPU richiede l'ottimizzazione delle applicazioni stesse, spesso di una riscrittura totale di intere parti di codice.
- Costo d'acquisto: il costo di una qualunque GPU è allineato a quello di una CPU appartenente alla stessa fascia di mercato, e questo consente di migliorare le cosiddette "prestazioni per watt" e di conseguenza l'efficienza dell'elaborazione.
- Tasso di aggiornamento tecnologico: il susseguirsi delle generazioni di architetture di GPU è ad oggi decisamente più veloce rispetto alle evoluzioni disponibili nel campo delle CPU.
- Consumo/prestazioni: l'enorme potenza elaborativa teorica delle GPU compensa grandemente l'elevato livello di consumo energetico e di conseguenza il rapporto consumo/prestazioni delle diverse soluzioni è a vantaggio delle GPU rispetto alle CPU.
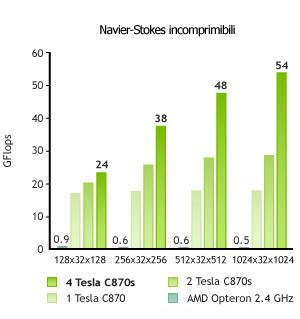
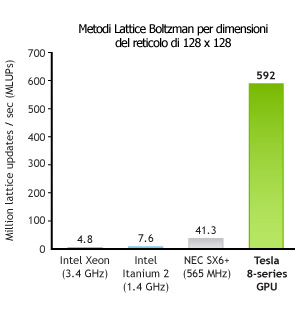
Un esempio: la fluidodinamica computazionale
Ci sono diversi progetti in corso sui modelli di Navier-Stokes e i metodi di Lattice Boltzman che hanno riscontrato una notevole accelerazione grazie alle GPU CUDA-compatibili. I risultati di questi progetti sono riassunti in alcuni grafici qui sotto, tratti dal sito ufficiale di CUDA. Sono inoltre in corso progetti sulla modellazione del clima e degli oceani basati sulle GPU CUDA-compatibili.
Riferimenti
http://gpgpu.org/about
http://en.wikipedia.org/wiki/GPGPU
http://it.wikipedia.org/wiki/GPGPU
http://www.nvidia.it/page/tesla_computing_solution...