2012
di Gianpaolo Perego, Aethia Srl
A & C - ANALISI E CALCOLO | MAGGIO 2012
Le CPU disponibili oggi sul mercato hanno un numero di core che va da 4 a16. Con schede madri a 4 socket si riesce oggi ad arrivare a 64 core su un singolo computer. In uno scenario di questo tipo acquistano sempre più importanza sia gli applicativi software “paralleli", in grado di distribuire il carico di lavoro su più core, sia i linguaggi e gli strumenti per scrivere applicativi paralleli.
Fra i vari approcci alla programmazione parallela, quello di
OpenMP è estremamente efficace in quanto permette con semplicità di parallelizzare porzioni selezionate di un programma.
Che cos'è OpenMP?
OpenMP è un sistema semplificato per convertire un programma che sfrutta una sola CPU in un programma capace di utilizzare più CPU assieme su sistemi a memoria condivisa (shared memory), quindi principalmente su singoli computer equipaggiati con più processori.
In generale quasi tutti i programmi che richiedono alte prestazioni hanno qualche tipo di “ciclo" (loop), ossia serie di operazioni simili ripetute n volte (cicli for). Spesso ogni iterazione di un ciclo for non ha nessuna interdipendenza con le altre, e in questi casi le iterazioni potrebbero essere eseguite in contemporanea fra loro, ottenendo una parallelizzazione del ciclo for. Produrre questo risultato con OpenMP richiede semplicemente di anteporre al ciclo for, all'interno del codice sorgente del programma, una direttiva di compilazione che indica che quel ciclo può essere svolto in parallelo. Ci penserà poi il compilatore a fare tutto il resto. Questo è l'aspetto chiave di OpenMP: inserendo semplici direttive di compilazione nei posti giusti si ottiene un impatto profondo nella velocità di esecuzione di un'applicazione. Anche se un programma è stato inizialmente concepito e scritto per essere eseguito su un solo processore, può risultare molto semplice adattarlo perché possa sfruttare, in punti particolari, la presenza di più core. Naturalmente ci sono molti altri aspetti che caratterizzano OpenMP, ma il vantaggio principale è proprio la possibilità di ottenere una parallelizzazione automatica dei programmi, quando possibile.
Come funziona?
Solitamente un programma consiste di parti che vanno eseguite in modo sequenziale, all'interno di un unico thread, e di parti che invece possono essere eseguite più velocemente impiegando più thread, come ad esempio alcuni lunghi cicli for. Quando si scrive un'applicazione con OpenMP, per default il codice viene eseguito da un unico thread chiamato master thread. Quando si arriva a un punto in cui l'esecuzione può essere presa in carico da un numero maggiore di thread, si possono usare le direttive di compilazione di OpenMP per delimitare queste porzioni di codice. In definitiva, quindi, in un programma OpenMP alcune parti di codice restano seriali, e altre vengono parallelizzate.
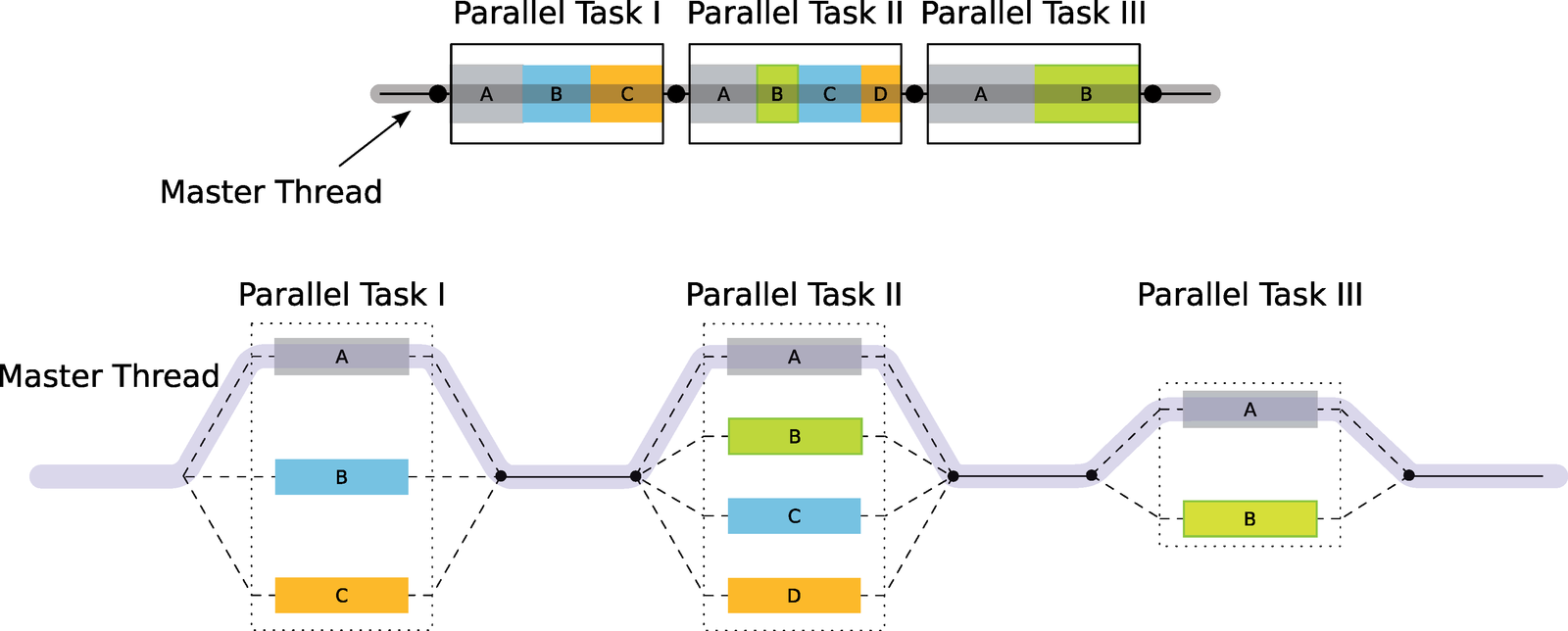
Per delimitare una sezione di codice che può essere eseguita in parallelo è sufficiente scrivere questo:
#pragma omp parallel
{
// Insert code here
}
Nello pseudo-code di esempio è stata inserita la direttiva di compilazione #pragma omp parallel per comunicare che tutto il codice all'interno delle parentesi graffe va eseguito su tutti i thread disponibili.
La memoria condivisa
Come dicevamo, le applicazioni OpenMP sono pensate per essere eseguite su singoli computer con memoria condivisa, come ad esempio un qualsiasi PC. Talvolta i thread hanno bisogno di utilizzare locazioni di memoria accessibili anche a tutti gli altri thread. Queste locazioni di memoria, essenzialmente variabili del programma, sono “condivise" nel senso che sono disponibili in modo consistente per tutti i thread. Altre volte un thread può aver bisogno di variabili che devono avere valori diversi e specifici per ogni singolo thread. Si parla in questo caso di variabili “private".
Ecco un esempio in linguaggio C:
#include <omp.h>
int main(int argc, char* argv[]) {
printf("Starting Program!n");
int nThreads, tid;
#pragma omp parallel private(tid) {
tid = omp_get_thread_num();
printf("Running on thread %dn", tid);
if (tid == 0) {
nThreads = omp_get_num_threads();
printf("Total number of threads: %dn", nThreads);
}
}
printf("Finished!n");
return 0;
}
Cicli for paralleli
Supponiamo di dover scrivere per esempio un programma che effettua il rendering di una scena 3D tramite il metodo del ray tracing. Senza entrare troppo nel dettaglio dell'algoritmo, il programma elabora ogni pixel dello schermo e determina il colore di quel pixel in base a informazioni sulla luce, sui materiali e sulle geometrie. Il processo viene ripetuto in questo modo per il pixel successivo e per tutti gli altri. La cosa importante da notare è che il calcolo del colore di ogni pixel è completamente indipendente dal calcolo del colore di qualsiasi altro pixel, cosa che apre la strada all'uso di OpenMP. Consideriamo lo pseudo-codice che segue:
#pragma omp parallel for
for(int x=0; x < width; x++) {
for(int y=0; y < height; y++)
finalImage[x][y] = RenderPixel(x,y, &sceneData);
}
Tralasciando momentaneamente la prima riga (#pragma …), il codice elabora iterativamente ogni pixel dello schermo, una colonna alla volta, e richiama la funzione RenderPixel() per determinare il colore finale da assegnare al pixel. Si noti che i risultati sono semplicemente memorizzati in un array. Considerando che la funzione RenderPixel() richiede un tempo rilevante per eseguire i propri calcoli, e che tali calcoli possono essere eseguiti in contemporanea per pixel diversi, questo ciclo for è un ottimo candidato per essere parallelizzato con OpenMP.
Considerando ora la riga inserita subito prima del ciclo for più esterno, questa direttiva di compilazione dice al compilatore di auto-parallelizzare il ciclo for con OpenMP. Se si sta usando un processore quad-core, ad esempio, ci si può attendere che le performance del programma aumentino almeno del 300% con la semplice aggiunta di una riga di codice. In generale, speed up lineari o super lineari dei tempi di calcolo sono molto rari, ma speed up quasi lineari sono molto comuni.
I concetti illustrati in questo breve articolo sono solo la punta dell'iceberg di tutto quello che può essere fatto con OpenMP. Si è cercato più che altro di far cogliere il fatto che questo strumento offre una semplicità di approccio alla programmazione parallela davvero unica. Per maggiori informazioni e approfondimenti si consiglia prima di tutto il sito web di riferimento di OpenMP.